如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
机器学习Machine Learning代写,免费提交作业要求, 满意后付款,成绩80\%以下全额退款,安全省心无顾虑。专业硕 博写手团队,所有订单可靠准时,保证 100% 原创。 最高质量的机器学习Machine Learning作业代写,服务覆盖北美、欧洲、澳洲等 国家。 在代写价格方面,考虑到同学们的经济条件,在保障代写质量的前提下,我们为客户提供最合理的价格。 由于作业种类很多,同时其中的大部分作业在字数上都没有具体要求,因此机器学习Machine Learning作业代写的价格不固定。通常在专家查看完作业要求之后会给出报价。作业难度和截止日期对价格也有很大的影响。
同学们在留学期间,都对各式各样的作业考试很是头疼,如果你无从下手,不如考虑my-assignmentexpert™!
my-assignmentexpert™提供最专业的一站式服务:Essay代写,Dissertation代写,Assignment代写,Paper代写,Proposal代写,Proposal代写,Literature Review代写,Online Course,Exam代考等等。my-assignmentexpert™专注为留学生提供Essay代写服务,拥有各个专业的博硕教师团队帮您代写,免费修改及辅导,保证成果完成的效率和质量。同时有多家检测平台帐号,包括Turnitin高级账户,检测论文不会留痕,写好后检测修改,放心可靠,经得起任何考验!
想知道您作业确定的价格吗? 免费下单以相关学科的专家能了解具体的要求之后在1-3个小时就提出价格。专家的 报价比上列的价格能便宜好几倍。
我们在计算机Quantum computer代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的计算机Quantum computer代写服务。我们的专家在机器学习Machine Learning代写方面经验极为丰富,各种机器学习Machine Learning相关的作业也就用不着 说。
计算机代写|机器学习代写Machine Learning代考|UNDERSTANDING THE IMPORTANCE OF SCOPING A RESEARCH (EXPERIMENT) PHASE
If the ML team members working on the personalization project had all the time in the world (and an infinite budget), they might have the luxury of finding an optimal solution for their problem. They could sift through hundreds of whitepapers, read through treatises on the benefits of one approach over another, and even spend time finding a novel approach to solve the specific use case that their business sees as an ideal solution. Not held back by meeting a release date or keeping their technical costs down, they could easily spend months, if not years, just researching the best possible way to introduce personalization to their website and apps.
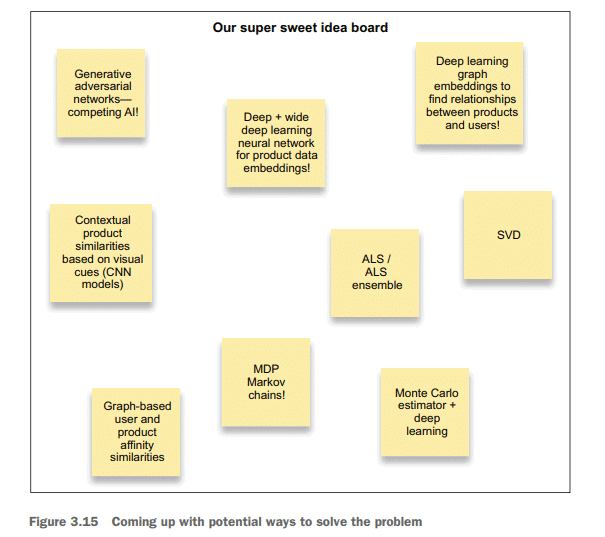
Instead of just testing two or three approaches that have been proven to work for others in similar industries and use cases, they could work on building prototypes for dozens of approaches and, through careful comparison and adjudication, select the absolutely best approach to create the optimal engine that would provide the finest recommendations to their users. They may even come up with a novel approach that could revolutionize the problem space. If the team were allowed to be free to test whatever they wanted for this personalized recommendation engine, the ideas whiteboard might look something like figure 3.15 .
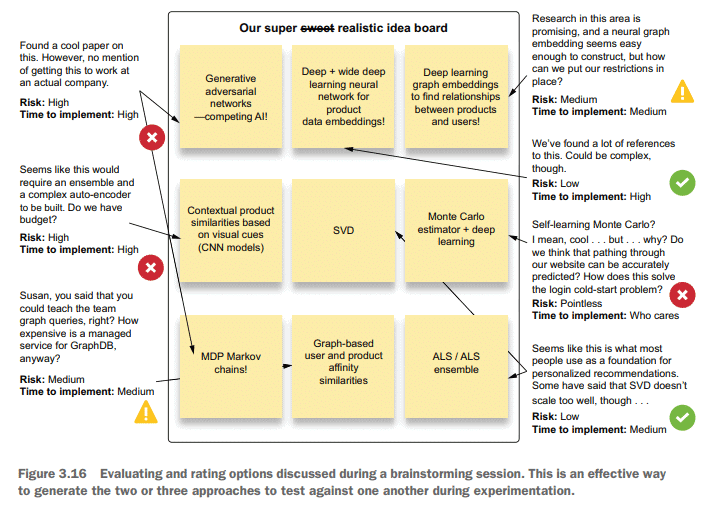
After a brainstorming session that generated these ideas (which bears striking resemblance to many ideation sessions I’ve had with large and ambitious DS teams), the next step that the team should take collectively is to start making estimations of these implementations. Attaching comments to each alternative can help formulate a plan of the two or three most likely to succeed within a reasonable time of experimentation. The commentary in figure 3.16 can assist the team with deciding what to test out to meet the needs of actually shipping a product to production.
After the team goes through the exercise of assigning risk to the different approaches, as shown in figure 3.16 , the most likely and least risky options can be decided on that fit within the scope of time allocated for testing. The primary focus of evaluating and triaging the various ideas is to ensure that plausible implementations are attempted. To meet the goals of the project (accuracy, utility, cost, performance, and business problem-solving success criteria), pursuing experiments that can achieve all of those goals is of the utmost importance.
计算机代写|机器学习代写Machine Learning代考|Total cost of ownership
While an analysis of the cost to maintain a project of this nature is nigh impossible to estimate accurately at the experimentation stage, it is an important aspect to consider and make an educated guess at.
During the experimentation, elements inevitably will be missing from the overall data architecture of the business. Services will likely need to be created for capturing data. Serving layers will need to be built. If the organization has never dealt with modeling around matrix factorization, it will need to potentially use a platform that it has never used before.
What if data can’t actually be acquired to satisfy the needs of the project, though? This is the time to identify show-stopping issues. Identify them, ask if solutions are going to be provided to support the needs of the implementation, and, if not, alert the team that without investment to create the needed data, the project should be halted.
Provided that there aren’t issues as severe as that, here are some questions to think about during this phase when gaps and critical issues are discovered:
What additional ETL do we need to build?
How often do we need to retrain models and generate inferences?
What platform are we going to use to run these models?
For the platform and infrastructure that we need, are we going to use a managed service or are we going to try to run it ourselves?
Do we have expertise in running and maintaining services for ML of this nature?
What is the cost of the serving layer plans that we have?
What is the cost of storage, and where will the inference data live to support this project?
You don’t have to answer each of these before development begins (other than the platform-related questions), but they should always be kept in mind as elements to revisit throughout the development process. If you don’t have sufficient budget to run one of these engines, perhaps a different project should be chosen.
机器学习代写
计算机代写|机器学习代写Machine Learning代考|UNDERSTANDING THE IMPORTANCE OF SCOPING A RESEARCH (EXPERIMENT) PHASE
如果致力于个性化项目的ML团队成员拥有所有的时间(以及无限的预算),他们可能会为他们的问题找到最佳解决方案。他们可以筛选数百份白皮书,通读一种方法优于另一种方法的论文,甚至花时间寻找一种新颖的方法来解决他们的业务视为理想解决方案的特定用例。如果不去赶发布日期或降低技术成本,他们很容易就会花上几个月,甚至几年的时间来研究在网站和应用中引入个性化的最佳方式。他们可以为几十种方法构建原型,并通过仔细的比较和评判,选择绝对最好的方法来创建最佳引擎,从而为用户提供最好的推荐,而不是仅仅测试两种或三种已经被证明适用于类似行业和用例的方法。他们甚至可能想出一种新颖的方法来彻底改变问题空间。如果团队可以自由地测试他们想要的个性化推荐引擎的任何内容,那么想法白板可能看起来像图3.15。
在产生这些想法的头脑风暴会议之后(这与我与许多大型和雄心勃勃的DS团队的想法会议惊人地相似),团队应该集体采取的下一步是开始评估这些实现。在每个备选方案上附加评论可以帮助在合理的实验时间内形成两到三个最有可能成功的方案。图3.16中的注释可以帮助团队决定测试哪些内容,以满足实际将产品交付生产的需求。
在团队将风险分配给不同的方法之后,如图3.16所示,最可能和风险最小的选项可以在分配给测试的时间范围内决定。评估和分类各种想法的主要焦点是确保尝试了合理的实现。为了达到项目的目标(准确性、实用性、成本、性能和业务问题解决的成功标准),追求能够实现所有这些目标的实验是至关重要的。
计算机代写|机器学习代写Machine Learning代考|Total cost of ownership
虽然在实验阶段对维持这种性质的项目的成本进行分析几乎是不可能准确估计的,但这是一个重要的方面,需要考虑并做出有根据的猜测。
在实验期间,业务的整体数据体系结构中不可避免地会缺少一些元素。可能需要创建用于捕获数据的服务。需要构建服务层。如果组织从未处理过围绕矩阵分解的建模,那么它可能需要使用以前从未使用过的平台。
但是,如果不能实际获取数据以满足项目的需要,该怎么办?现在是时候找出那些引人注目的问题了。确定它们,询问是否将提供解决方案来支持实现的需求,如果没有,则提醒团队,如果没有投资来创建所需的数据,则应该停止项目。
假设没有那么严重的问题,当发现差距和关键问题时,在此阶段需要考虑以下一些问题:
我们需要构建哪些额外的ETL ?我们多久需要重新训练模型并生成推理?我们将使用什么平台来运行这些模型?对于我们需要的平台和基础设施,我们是使用托管服务还是尝试自己运行它?我们在运行和维护这种性质的机器学习服务方面有专业知识吗?
我们拥有的服务层计划的成本是多少?
存储成本是多少?为了支持这个项目,推理数据将驻留在哪里?
你不必在开发开始之前回答所有这些问题(除了与平台相关的问题),但在整个开发过程中,你应该始终牢记这些元素。如果你没有足够的预算来运行这些引擎中的一个,也许应该选择一个不同的项目。

计算机代写|机器学习代写Machine Learning代考 请认准UprivateTA™. UprivateTA™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。